背景
HiTSDB时序数据库引擎在服务于阿里巴巴集团内的客户时,根据集团业务特性做了很多针对性的优化。 然而在HiTSDB云产品的打磨过程中逐渐发现,很多针对性的优化很难在公有云上针对特定用户去实施。
于此同时, 在公有云客户使用HiTSDB的过程中,发现了越来越多由于聚合查询导致的问题,比如: 返回数据点过多会出现栈溢出等错误,聚合点过多导致OOM, 或者无法完成聚合,实例完全卡死等等问题。这些问题主要由于原始的聚合引擎架构上的缺陷导致。
因此HiTSDB开发团队评估后决定围绕新的聚合引擎架构对HiTSDB引擎进行升级,包含: 存储模型的改造,索引方式的升级,实现全新的流式聚合,数据迁移,性能评测。本文主要围绕这5个方面进行梳理,重点在“全新的流式聚合部分”。
1. 时序数据存储模型:
1.1 时序的数据存储格式。
一个典型的时序数据由两个维度来表示,一个维度表示时间轴,随着时间的不断流入,数据会不断地追加。 另外一个维度是时间线,由指标和数据源组成,数据源就是由一系列的标签标示的唯一数据采集点。例如指标cpu.usage的数据来自于机房,应用,实例等维度组合成的采集点。 这样大家逻辑上就可以抽象出来一个id+{timestamp, value}的时序数据模型。这种数据模型的存储是如何呢。一般有两种典型的数据存储思路:
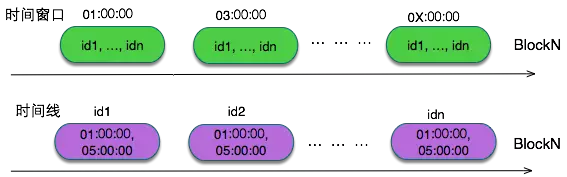
一种按照时间窗口维度划分数据块,同一段自然时间窗口内的连续数据放到相邻的位置,比如{1:00, 2:00}->(id1, id2, id3, ... ... ,idN)。 采用这种方式的典型时序数据库包含InfluxDB, Promethues等等TSMT结构的数据库。OpenTSDB有些特殊,因为OpenTSDB是单值模型,指标这个维度在查询的时候是必带的。 所以可以先按照指标做了一级划分,再根据时间窗口做二级的划分,本质上还是同一时间窗口内的连续数据。 按照时间窗口切分的方式,优势是写入的时候可以很天然的按照窗口去落盘,对于高纬度的标签查询基本上是一些连续Scan. 这种方式有个比较难解的问题就是"out of order"乱序问题,对于时间窗口过期后再来的时间点,Promethues直接采用丢弃的方式,InfluxDB在这种情况下性能会有损耗。
另外一种按照时间线维度划分数据块,同一时间线的数据放到相邻的位置,比如(id1)->(1:00, 2:00, 3:00, ... ... , 23:00)。 HiTSDB采用时间线维度划分的方式:目前落盘数据存储于HBASE,底层Rowkey由指标+标签+自然窗口的方式组合而成. Rowkey按照大小顺序合并某个时间线的数据点是连续相邻的。 因此对于一些低维的查询效率是非常高效的。根据目前接触的一些物联网服务,更多的是一些低维的访问。对于中等维度的查询采用流式scan。对于极高纬度标签的查询HiTSDB采用预聚合的服务(不在本文讨论范围内)。
1.2 时序模型的热点问题处理
生产环境中业务方采集的指标类型多种多样,对指标的采集周期各不相同。比如cpu.usage这个指标的变化频率比较快,业务方关注度高,采集周期通常很短,1秒,5秒,10秒等等。 然而指标disk.usage这个指标变化趋势相对平滑,采集周期通常为1分钟,5分钟, 10分钟等。这种情况下,数据的存储如果针对同一个指标不做特殊处理,容易形成热点问题。 假设按照指标类型进行存储资源的分片,想象一下如果有20个业务,每个业务10个集群,每个集群500台主机,采集周期是1秒的话,每秒就会有10万个cpu.usage的指标数据点落到同一个存储资源实例中, 而disk.usage采集周期为1分钟,所以大约只有1666个指标数据点落到另外一个存储资源上,这样数据倾斜的现象非常严重。
1.2.1 分桶
这类问题的经典解法就是分桶。比如除了指标类型外,同时将业务名和主机名作为维度标识tags,把指标cpu.usage划分到不同的桶里面。 写入时根据时间线哈希值分散写入到不同的桶里面。 OpenTSDB在处理热点问题也是采用了分桶模式,但是需要广播读取,根本原因在于查询方式需要在某个时间窗口内的全局扫描。 所以设置OpenTSDB的分桶数量需要一个平衡策略,如果数量太少,热点还是有局部性的问题,如果太多,查询时广播读带来的开销会非常大。
与其相比较,HiTSDB避免了广播读,提高了查询效率。由于HiTSDB在查询时,下发到底层存储扫描数据之前,首先会根据查询语句得到精确命中的时间线。 有了具体的时间线就可以确定桶的位置,然后到相应的块区域取数据,不存在广播读。 关于HiTSDB如何在查询数据的时候获取命中的时间线,相信读者这个疑问会在读取完倒排这一节的时候消释。
1.2.2 Region Pre-Split
当一个表刚被创建的时候,HBase默认分配一个Region给新表。所有的读写请求都会访问到同一个regionServer的同一个region中。 此时集群中的其他regionServer会处于比较空闲的状态,这个时候就达不到负载均衡的效果了。 解决这个问题使用pre-split,在创建新表的时候根据分桶个数采用自定义的pre-split的算法,生成多个region。 byte[][] splitKeys =new byte[bucketNumber-1][]; splitKeys[bucketIndex-1] = (bucketIndex&0xFF);

2. 倒排索引:
2.1 时序数据中的多维时间线
多维支持对于任何新一代时序数据库都是极其重要的。 时序数据的类型多种多样,来源更是非常复杂,不止有单一维度上基于时间的有序数值,还有多维时间线相关的大量组合。 举个简单例子,cpu的load可以有三个维度描述cpu core, host, app应用,每个维度可以有百级别甚至万级别的标签值。 sys.cpu.load cpu=1 host=ipA app=hitsdb,各个维度组合后时间线可以轻松达到百万级别。 如何管理这些时间线,建立索引并且提供高效的查询是时序数据库里面需要解决的重要问题。 目前时序领域比较主流的做法是采用倒排索引的方式。
2.2 倒排索引基本组合
基本的时间线在倒排中的组合思路如下:
时间线的原始输入值:
idtime series
|
|
1 |
sys.cpu.load cpu=1 host=ipA app=hitsdb |
2 |
sys.cpu.load cpu=2 host=ipA app=hitsdb |
3 |
sys.cpu.load cpu=3 host=ipA app=hitsdb |
4 |
sys.cpu.load cpu=4 host=ipA app=hitsdb |
5 |
sys.cpu.load cpu=1 host=ipB app=hitsdb |
6 |
sys.cpu.load cpu=2 host=ipB app=hitsdb |
7 |
sys.cpu.load cpu=3 host=ipB app=hitsdb |
8 |
sys.cpu.load cpu=4 host=ipB app=hitsdb |
倒排构建后:
termposting list
|
|
cpu=1 |
1,5 |
cpu=2 |
2,6 |
cpu=3 |
3,7 |
cpu=4 |
4,8 |
host=ipA |
1,2,3,4 |
host=ipB |
5,6,7,8 |
app=histdb |
1,2,3,4,5,6,7,8 |
查询时间线 cpu=3 and host=ipB:
termposting list
|
|
cpu=3 |
3,7 |
host=ipB |
5,6,7,8 |
取交集后查询结果为7:
idtime series
|
|
7 |
sys.cpu.load cpu=3 host=ipB app=hitsdb |
2.3 倒排面临的问题以及优化思路
倒排主要面临的是内存膨胀的问题:
posting list过长, 对于高纬度的tag,比如“机房=杭州”,杭州可能会有千级别甚至万级别的机器,这就意味着posting list需要存储成千上万个64-bit的id。 解决这个问题的思路是采用压缩posting list的方式, 在构建posting list的时候对数组里面的id进行排序,然后采用delta编码的方式压缩。
如果Tag键值对直接作为term使用,内存占用取决于字符串的大小,采用字符串字典化,也可大大减少内存开销。


