3. 流式聚合引擎
3.1 HiTSDB聚合引擎的技术痛点
HiTSDB现有聚合引擎公有云公测以及集体内部业务运行中,暴露发现了以下问题:
3.1.1 Materialization执行模式造成Heap内存易打爆
下图显示了原查询引擎的架构图。HiTSDB以HBase作为存储,原引擎通过Async HBase client 从HBase获取时序数据。由于HBase的数据读取是一个耗时的过程,通常的解法是采用异步HBase client的API,从而有效提高系统的并行性。但原聚合引擎采用了一种典型的materialization的执行方式:1)启动多个异步HBase API启HBase读,2)只有当查询所涉及的全部时序数据读入到内存中后,聚合运算才开始启动。这种把HBase Scan结果先在内存中materialized再聚合的方式使得HiTSDB容易发生Heap内存打爆的现象。尤其当用户进行大时间范围查询,或者查询的时间线的数据非常多的时候,因为涉及的时序数据多,HiTSDB会发生Heap OOM而导致查询失败。
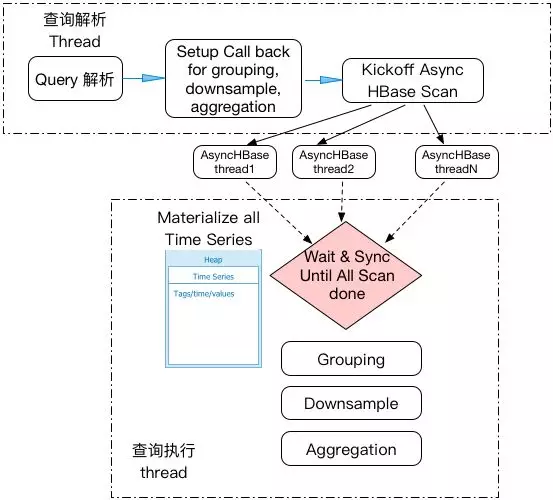
3.1.2 大查询打爆HBase的问题
两个原因造成HiTSDB处理聚合查询的时候,容易发生将底层HBase打爆。
HBase 可能读取多余时间线数据。HiTSDB的时间线采用指标+时间窗口+标签的编码方式存储在HBase。典型的查询是用户指定一个指标,时间范围,以及空间维度上标签要寻找的匹配值。空间维度的标签查询条件并不都是在标签编码前缀。当这种情况发生时,HiTSDB倒排索引不能根据空间维度的查询条件,精确定位到具体的HBase的查询条件,而是采用先读取再过滤的方式。这意味着HBase有可能读取很多冗余数据,从而加重HBase的负载。
HiTSDB有可能在短时间内下发太多HBase读请求。一方面,HiTSDB在HBase采用分片存储方式,对每一个分片,都至少启动一个读请求,另一方面,因为上面提到的materialization的执行方式,一个查询涉及到的HBase读请求同时异步提交,有可能在很短时间内向HBase下发大量的读请求。这样,一个大查询就有可能把底层的HBase打爆。
当这种情况发生时,更糟糕的场景是HiTSDB无法处理时序数据的写入请求,造成后续新数据的丢失。
3.1.3 执行架构高度耦合,修改或增加功能困难
聚合引擎主要针对应用场景是性能监控,查询模式固定,所以引擎架构采用单一模式,把查询,过滤,填值/插值,和聚合运算的逻辑高度耦合在一起。这种引擎架构对于监控应用的固定查询没有太多问题,但HiTSDB目标不仅仅是监控场景下的简单查询,而是着眼于更多应用场景下的复杂查询。
我们发现采用原有引擎的架构,很难在原有基础上进行增加功能,或修改原来的实现。本质上的原因在于原有聚合引擎没有采用传统数据库所通常采用的执行架构,执行层由可定制的多个执行算子组成,查询语义可以由不同的执行算子组合而完成。这个问题在产品开发开始阶段并不感受很深,但确是严重影响HiTSDB拓宽应用场景,增加新功能的一个重要因素。
3.1.4 聚合运算效率有待提高
原有引擎在执行聚合运算的时候,也和传统数据库所通常采用的iterative执行模式一样,迭代执行聚合运算。问题在于每次iteration执行,返回的是一个时间点。Iterative 执行每次返回一条时间点,或者一条记录,常见于OLTP这样的场景,因为OLTP的查询所需要访问的记录数很小。但对HiTSDB查询有可能需要访问大量时间线数据,这样的执行方式效率上并不可取。
原因1)每次处理一个时间点,都需要一系列的函数调用,性能上有影响,2)iterative循环迭代所涉及到的函数调用,无法利用新硬件所支持的SIMD并行执行优化,也无法将函数代码通过inline等JVM常用的hotspot的优化方式。在大数据量的场景下,目前流行的通用做法是引入Vectorization processing, 也就是每次iteration返回的不再是一条记录,而是一个记录集(batch of rows),比如Google Spanner 用batch-at-a-time 代替了row-at-a-time, Spark SQL同样也在其执行层采用了Vectorization的执行模式。
3.2 流式聚合引擎设计思路
针对HiTSDB原有聚合运算引擎上的问题,为了优化HiTSDB,支持HiTSDB商业化运营,我们决定改造HiTSDB聚合运算引擎。下图给出了新聚合查询引擎的基本架构。
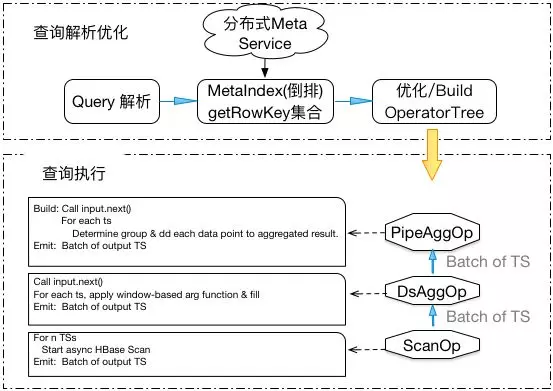
3.2.1 pipeline执行模式
借鉴传统数据库执行模式,引入pipeline的执行模式(aka Volcano / Iterator 执行模式)。Pipeline包含不同的执行计算算子(operator), 一个查询被物理计划生成器解析分解成一个DAG或者operator tree, 由不同的执行算子组成,DAG上的root operator负责驱动查询的执行,并将查询结果返回调用者。在执行层面,采用的是top-down需求驱动 (demand-driven)的方式,从root operator驱动下面operator的执行。这样的执行引擎架构具有优点:
这种架构方式被很多数据库系统采用并证明是有效;
接口定义清晰,不同的执行计算算子可以独立优化,而不影响其他算子;
易于扩展:通过增加新的计算算子,很容易实现扩展功能。比如目前查询协议里只定义了tag上的查询条件。如果要支持指标值上的查询条件(cpu.usage >= 70% and cpu.usage <=90%),可以通过增加一个新的FieldFilterOp来实现。
每个operator,实现如下接口:
我们在HiTSDB中实现了以下算子:
3.2.2 执行计算算子一个batch的时间线数据为运算单位
在计算算子之间以一个batch的时间线数据为单位,提高计算引擎的执行性能。其思想借鉴于OLAP系统所采用的Vectorization的处理模式。这样Operator在处理一个batch的多条时间线,以及每条时间线的多个时间点,能够减少函数调用的代价,提高loop的执行效率。
每个Operator以流式线的方式,从输入获得时间线batch, 经过处理再输出时间线batch, 不用存储输入的时间线batch,从而降低对内存的要求。只有当Operator的语义要求必须将输入materialize,才进行这样的操作(参见下面提到的聚合算子的不同实现)。
3.2.3. 区分不同查询场景,采用不同聚合算子分别优化
HiTSDB原来的聚合引擎采用materialization的执行模式,很重要的一个原因在于处理时序数据的插值运算,这主要是因为时序数据的一个典型特点是时间线上不对齐:不同的时间线在不同的时间戳上有数据。HiTSDB兼容OpenTSDB的协议,引入了插值(interpolation)的概念,目的在于聚合运算时通过指定的插值方式,在不对齐的时间戳上插入计算出来的值,从而将不对齐的时间线数据转换成对齐的时间线。插值是在同一个group的所有时间线之间比较,来决定在哪个时间戳上需要进行插值 (参见OpenTSDB 文档)。
为了优化聚合查询的性能,我们引入了不同的聚合运算算子。目的在于针对不同的查询的语义,进行不同的优化。有些聚合查询需要插值,而有些查询并不要求插值;即使需要插值,只需要把同一聚合组的时间线数据读入内存,就可以进行插值运算。
PipeAggOp: 当聚合查询满足以下条件时,
1)不需要插值: 查询使用了降采样(downsample),并且降采样的填值采用了非null/NaN的策略。这样的查询,经过降采样后,时间线的数据都是对齐补齐的,也就是聚合函数所用到的插值不再需要。
2)聚合函数可以支持渐进式迭代计算模式 (Incremental iterative aggregation), 比如sum, count ,avg, min, max, zerosum, mimmim, mimmax,我们可以采用incremental聚合的方式,而不需要把全部输入数据读入内存。这个执行算子采用了流水线的方式,每次从输入的operator获得一系列时间线,计算分组并更新聚合函数的部分值,完成后可以清理输入的时间线,其自身只用保留每个分组的聚合函数的值。
MTAgOp: 需要插值,并且输入算子无法帮助将时间线ID预先分组,这种方式回退到原来聚合引擎所采用的执行模式。
对于MTAggOp, 我们可以引入分组聚合的方法进行优化:
3.2.4 查询优化器和执行器
引入执行算子和pipeline执行模式后,我们可以在HiTSDB分成两大模块,查询优化器和执行器。优化器根据查询语义和执行算子的不同特点,产生不同的执行计划,优化查询处理。例如HiTSDB可以利用上面讨论的三个聚合运算算子,在不同的场景下,使用不同的执行算子,以降低查询执行时的内存开销和提高执行效率为目的。这样的处理方式相比于原来聚合引擎单一的执行模式,更加优化。


