4. 数据迁移
HiTSDB新的聚合引擎采用的底层存储格式与以前的版本并不兼容。 公有云公测期间运行在旧版本实例的数据,需要迁移至新的聚合引擎。 同时热升级出现了问题,数据迁移还应回滚功能,将新版本的数据点转换成旧的数据结构,实现版本回滚。 整体方案对于用户的影响做到:写入无感知,升级过程中,历史数据不可读。
4.1 数据迁移架构
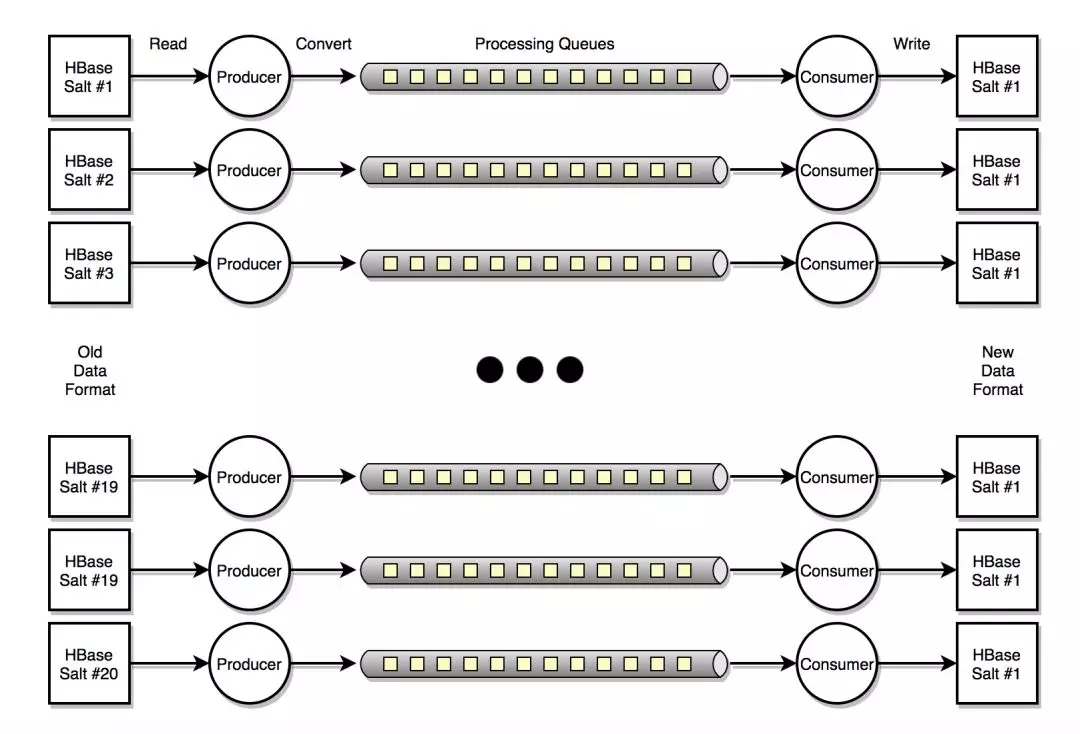
并发转换和迁移数据: 原有的HiTSDB数据点已经在写入的时候进行了分片。默认有20个Salts。数据迁移工具会对每个Salt的数据点进行并发处理。 每个“Salt”都有一个Producer和一个Consumer。Producer负责开启HBase Scanner获取数据点。 每个Scanner异步对HBase进行扫描,每次获取HBASE_MAX_SCAN_SIZE行数的数据点。然后将HBase的Row Key转换成新的结构。
最后将该Row放到所有的一个Queue上等待Consumer消费。 Consumer每次会处理HBASE_PUT_BATCHSIZE或者HBASE_PUT_MIN_DATAPOINTS的数据量。 每次Consumer顺利写入该Batch的时候,我们会在UID表中记录对应“Salt”的数据处理位置。 这样便于故障重启时Producer从最后一次成功的地方重新开始获取数据点进行转换。 数据迁移工具对HBase的操作都采用异步的读写。当扫描数据或者写入数据失败的时候,我们会进行有限制的尝试。 如果超出尝试次数,我们就终止该“Salt”的数据迁移工作,其他”Salt“的工作不受到任何影响。 当下次工具自动重启时,我们会出现问题的”Salt“数据继续进行迁移,直到所有数据全部顺利转换完成。
流控限制: 大部分情况下,Producer对HBase的扫描数据要快于Consumer对HBase的写入。 为了防止Queue的数据积压对内存造成压力同时为了减少Producer扫描数据时对HBase的压力,我们设置了流控。 当Queue的大小达到HBASE_MAX_REQUEST_QUEUE_SIZE时候,Producer会暂时停止对HBase的数据扫描等待Consumer消费。 当Queue的大小减少到HBASE_RESUME_SCANNING_REQUEST_QUEUE_SIZE时候,Producer会重新恢复。
Producer和Consumer进程的退出
顺利完成时候如何退出: 当一切进展顺利时候,当Producer完成数据扫描之后,会在Queue上放一个EOS(End of Scan),然后退出。 Consumer遇到EOS就会知道该Batch为最后一批,成功处理完该Batch之后就会自动退出。
失败后如何关闭: Consumer遇到问题时:当Consumer写入HBase失败之后,consumer会设置一个Flag,然后退出线程。 每当Producer准备进行下一个HBASE_MAX_SCAN_SIZE的扫描时候,他会先检查该Flag。 如果被设置,他会知道对应的Consumer线程已经失败并且退出。Producer也会停止扫描并且退出。 Producer遇到问题时:当Producer扫描数据失败时,处理方式和顺利完成时候类似。都是通过往Queue上EOS来完成通知。 下次重启时,Producer会从上次记录的数据处理位置开始重新扫描。
4.2 数据迁移的一致性
由于目前云上版本HiTSDB为双节点,在结点升级结束后会自动重启HiTSDB。自动启动脚本会自动运行数据迁移工具。 如果没有任何预防措施,此时两个HiTSDB节点会同时进行数据迁移。虽然数据上不会造成任何丢失或者损坏, 但是会对HBase造成大量的写入和读取压力从而严重影响用户的正常的写入和查询性能。
为了防止这样的事情发生,我们通过HBase的Zoo Keeper实现了类似FileLock锁,我们称为DataLock,的机制保证只有一个结点启动数据迁移进程。 在数据迁移进程启动时,他会通过类似非阻塞的tryLock()的形式在Zoo Keeper的特定路径创建一个暂时的节点。 如果成功创建节点则代表成果获得DataLock。如果该节点已经存在,即被另一个HiTSDB创建,我们会收到KeeperException。这样代表未获得锁,马上返回失败。 如果未成功获得DataLock,该节点上的数据迁移进程就会自动退出。成果获得DataLock的节点则开始进行数据迁移。

4.3 数据迁移中的"执行一次"
当所有“Salt”的数据点全部顺利完成迁移之后,我们会在HBase的旧表中插入一行新数据,data_conversion_completed。 此行代表了数据迁移工程全部顺利完成。同时自动脚本会每隔12个小时启动数据迁移工具,这样是为了防止上次数据迁移没有全部完成。 每次启动时,我们都会先检查“data_conversion_completed”标志。如果标志存在,工具就会马上退出。 此项操作只会进行一次HBase的查询,比正常的健康检查成本还要低。所以周期性的启动数据迁移工具并不会对HiTSDB或者HBase产生影响。
4.4. 数据迁移的评测
测试机型: 4core,8G,SSD
采集写入间隔数据点量存储行测试结果
|
|
|
|
1秒 |
28.8亿 |
80万 |
迁移TPS 20W, 10G存储量/小时 |
10秒 |
3.6亿 |
100万 |
迁移TPS 19W, 9G存储量/小时 |
1小时 |
1000万 |
1000万 |
迁移 13W,6G存储量/小时 |
效果:上线后无故障完成100+实例数据的迁移,热升级。
5. 查询性能评测
测试环境配置
192.168.12.3 2.1.5版本
192.168.12.4 2.2.0版本(Pipelined Engine)
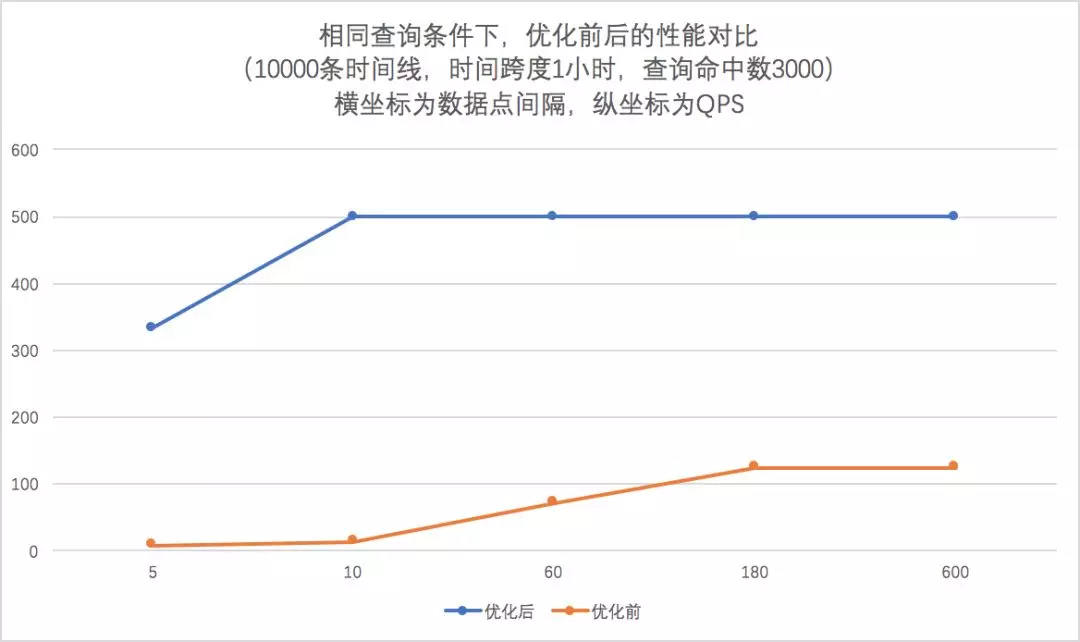
测试数据 - 1万条时间,不同的采集频率和时间窗口,还有查询命中的时间线数量。
Case 1: 数据采集频率5s, 查询命中1000条,时间窗口3600s
测试环境版本测试结果
|
|
2.1.5 |
max rt = 628 ms, min rt = 180 ms. avg rt = 191 |
2.2.2 |
max rt = 136 ms, min rt = 10 ms. avg rt = 13 |
Case 2: 数据采集频率1s,查询命中1条,时间窗口36000s
测试环境版本测试结果
|
|
2.1.5 |
max rt = 1803 ms, min rt = 1803 ms. avg rt = 1803 |
2.2.2 |
max rt = 182 ms, min rt = 182 ms. avg rt = 182 |
总结: 新的查询聚合引擎将查询速度提高了10倍以上。